Machine learning security
Machine learning (and artificial intelligence in general) is a hot topic, with a very diverse set of use cases. Among other things, it can be used for data mining, natural language processing or self-driving vehicles; it also has cyber security applications such as intrusion detection. In machine learning today we basically do structured deep learning. We apply the good old backpropagation technique and using artificial neural networks (AANs), just as we did decades ago. But this time with much (much!) more processing power.
Despite the large variance of technologies and use cases, all machine learning solutions have one thing in common. Just as any software system, they may be vulnerable in various ways, and so represent a potential target for attackers. Some recent demonstrations of potentially malicious interference include researchers making themselves invisible to surveillance systems, tricking the Tesla autopilot to accelerate past the speed limit, or giving imperceptible commands to speech recognition systems used by personal AI assistants.
Things do not look good: machine learning security is becoming a critical topic. However, many experts and practitioners are not even aware of the attack techniques. Not even those that have been known to the software security community for a long time. Neither do they know about the corresponding best practices. This should change.
An essential cyber security prerequisite is: ‘Know your enemy!’. So, for starters, it’s worthwhile to take a look at what the attackers are going to target in machine learning!
It all starts with the attack surface
The Garbage In, Garbage Out (GIGO) problem is well known in the machine learning world. Since all algorithms use training data to establish and refine their behavior, bad data will result in unexpected behavior. This can happen due to the neural network overfitting or underfitting the model, or due to problems with the dataset. Biased, faulty, or ambiguous training data are of course accidental problems, and there are ways to deal with them. For instance, by using appropriate testing and validation datasets. However, an adversary feeding in such bad input intentionally is a completely different scenario for which we also need special protection approaches.
Simply, we must assume that there will be malicious users: attackers. In our model they don’t have any particular privileges within the system, but they can provide raw input as training data, and can see the system’s output, typically the classification value. This already means that they can send purposefully bad or malicious data to trigger inadvertent machine learning errors (forcing GIGO).
But that’s just the tip of the iceberg…
First of all, attackers are always working towards a goal. To that end, they will target specific aspects of the machine learning solution. By choosing the right input, they can actually do a lot of potential damage to the model, the generated prediction, and even the various bits of code that process this input. Attackers are also smart. They are not restricted to sending static inputs – they can learn how the model works and refine their inputs to adapt the attack. They can even use their own ML system for this! In many scenarios, they can keep doing this over and over until the attack is successful.
All parts of the system where attackers can have direct influence on the input and/or can have access to the output form the attack surface. In case of supervised learning, it encompasses all three major steps of the machine learning workflow:
- For training, an attacker may be able to provide input data.
- For classification, an attacker can provide input data and read the classification result.
- If the ML system has feedback functionality, an attacker may also be able to give false feedback (‘wrong’ for a good classification and ‘correct’ for a bad classification) to confuse the system.
To better understand what an attacker can accomplish at these particular steps, let’s build a threat model.
Machine learning security: (mostly) the same old threats
In all cases, the attacker will want to damage a particular security requirement (the famous CIA triad, namely Confidentiality, Integrity and Availability) of an important system asset. Let’s take a look at these goals by using an ML-based facial recognition system for the examples:
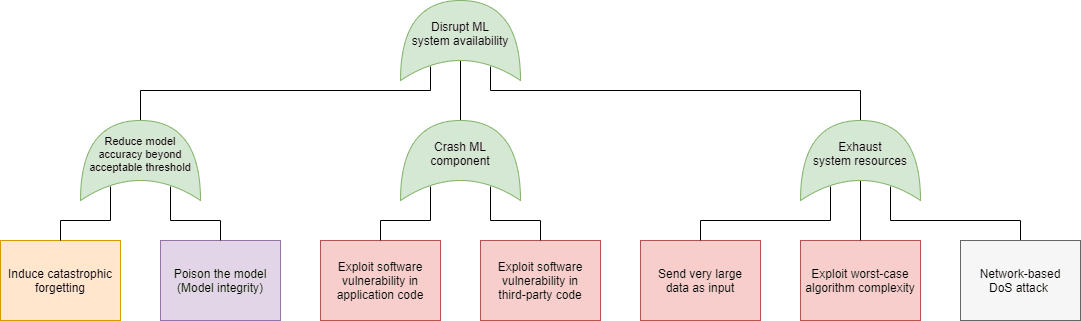
- Disruption (Availability of the entire system): Make the AI/ML system useless for its original purpose and consequently destroy trust in the system – e.g. the system no longer recognizes employees.
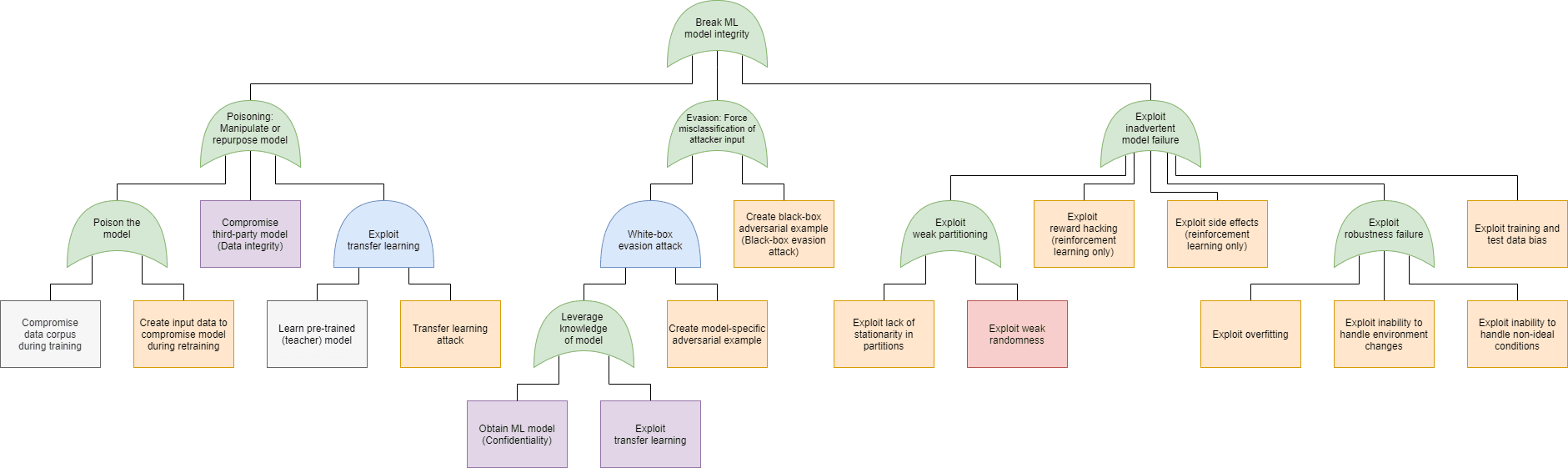
- Poisoning (Integrity of the model): Repurpose the system for their own benefit – e.g. the system incorrectly recognizes the attacker as the CEO (you can think of this as spoofing).
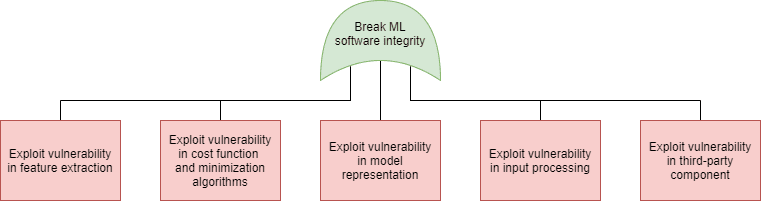
- Evasion (Integrity of the entire system): Avoid their own data getting classified (correctly, or at all) – e.g. the system does not recognize the attacker at all.
- Disclosure (Confidentiality of private user data): Steal private data – e.g. the attacker obtains the reference photos of the users that were used to train the system.
- Industrial espionage (Confidentiality of the model): Steal the model itself – e.g. the attacker obtains the exact weights, bias values, and hyperparameters used in the neural network.
Just as in case of software security, in machine learning security we can use the attack tree modeling technique to plot the possible attacks that can be used to realize these goals. On the following figures we have marked the specific attacks with the following colors:
- Blue: AND connection (all child elements need to succeed for the attack to succeed)
- Green: OR connection (at least one of the child elements needs to succeed for the attack to succeed)
- Purple: Expanded in a different attack tree node, as indicated in the box
- Orange: An attack that exploits a weakness in the machine learning process
- Red: An attack that exploits a weakness in the underlying code
- Grey: An attack included for the sake of completeness, but out of scope for software security. Note that in this model we did not include any physical attacks (sensor blinding, for instance).
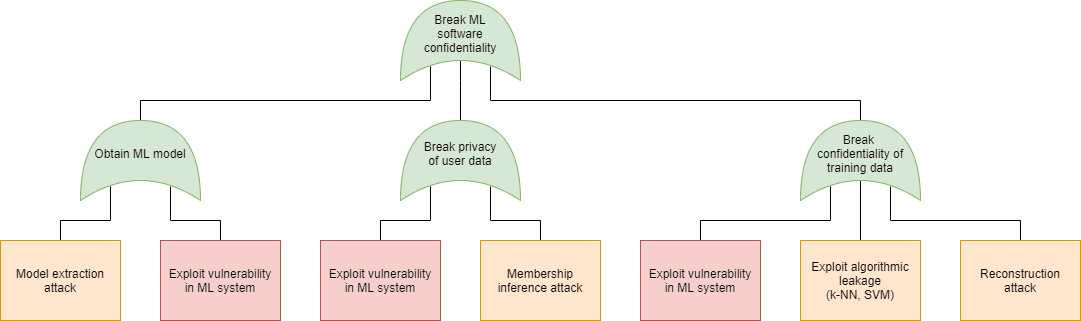 |
 |
| Confidentiality | Availability |
 |
|
| Integrity (Model) | |
 |
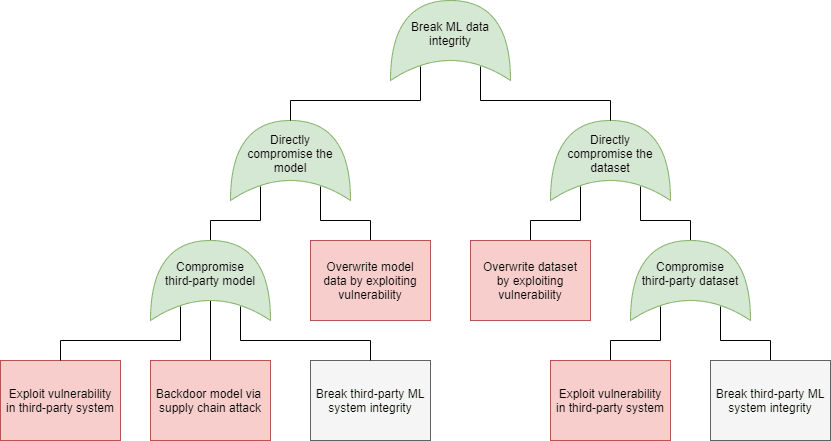 |
| Integrity (Software) | Integrity (Data) |
| Machine learning security – attack trees (click on the images to enlarge them) | |
Adversarial learning: one dumb cat, lots of smart mice
Many of the attacks described in the previous section make use of so-called adversarial examples. These crafted inputs either exploit the implicit trust an ML system puts in the training data received from the user to damage its security (poisoning) or trick the system into mis-categorizing its input (evasion). No foolproof method exists currently that can automatically detect and filter these examples; even the best solution (adversarial training) is limited in scope. On one hand, ML systems are pretty much like newborn babies that rely entirely on their parents to learn how the world works (including ‘backdoors’ such as fairy tales, or Santa Claus). On the other hand, ML systems are also like old cats with poor eyesight – when a mouse learns how the cat hunts, it can easily avoid being seen and caught.
There are defenses for detecting or mitigating adversarial examples, of course. Many of them however just do some kind of obfuscation of the results to make the attacker’s job harder (some of them even relying on security by obscurity). An intelligent attacker can defeat all of these solutions by producing a set of adversarial examples in an adaptive way. This has been highlighted by several excellent papers over the years (Towards Evaluating the Robustness of Neural Networks, Obfuscated Gradients Give a False Sense of Security: Circumventing Defenses to Adversarial Examples, On Evaluating Adversarial Robustness, On Adaptive Attacks to Adversarial Example Defenses). All in all, machine learning security research is still in its early stages. They mostly focused on image recognition thus far; however, some defense techniques that work well for images may not be effective with e.g. text or audio data.
That said, there are plenty of things you can still do to protect yourself in practice. Unfortunately, none of these techniques will protect you completely from malicious activities. All of them will however add to the protection, making the attacks harder. This is following the principle of defense in depth.
- Most importantly, think with the head of an attacker. Train the neural network with adversarial samples to make it explicitly recognize them (or variants of them) as incorrect. It is a good idea to create and use adversarial samples from all currently known attack techniques. A test framework can generate such samples to make the process easier. There are existing security testing tools that can help with this: ML fuzz testers can automatically generate invalid or unexpected input. Some examples are TensorFuzz and DeepTest.
- Limiting the attacker’s capabilities to send adversarial samples is always a good mitigation technique. One can easily achieve this by simply limiting the rate of inputs accepted from one user. Of course, detecting that the same user is behind a set of inputs might not be easy. This is the same challenge as in case of distributed denial of service attacks, and the same solutions might work as well.
- As always in software security, input validation can also help. Of course, it may not be trivial to automatically tell good inputs from bad ones; but it is definitely worth trying.
- As a ‘hair of the dog’ solution, we can use machine learning itself to identify anomalous patterns in input. In the simplest case, if data received from an untrusted user is consistently closer to the classification boundary than to the average, we can flag the data for manual review, or just omit it.
- Applying regular sanity checks with test data can also help. Running the same test dataset against the model upon each retraining cycle can uncover poisoning attack attempts. RONI (Reject On Negative Impact) is a typical defense here, detecting if the system’s capability to classify the test dataset degrades after the retraining.

Machine learning security is software security
We often overlook the most obvious fact about machine learning security: that ML solutions are essentially software systems. We write them in a certain programming language (usually Python, or possibly C++), and thus they potentially carry all common security weaknesses that apply to those languages. Furthermore, do not forget about A9 from the OWASP Top Ten – Using components with known vulnerabilities: any vulnerability in a widespread ML framework such as TensorFlow (or one of its many dependencies) can have far-reaching consequences for all of the applications that use it.
The attackers interact with the ML system by feeding in data through the attack surface. As already mentioned, let’s start to think with the head of the attacker and ask some questions. How does the application process this data? What form does it take? Does the system accept many different types of inputs, such as image, audio and video files, or does it restrict the users to just one of these? If so, how does it check for the right file type? Does the program do any parsing, or does it delegate it entirely to a third-party media library? And after preprocessing the data, does the program have any assumptions (e.g. a certain field must not be empty, or a value in another field must be between 0 and 255)? Is there any (meta)data stored in XML, JSON, or a relational database? If so, what kind of operations does the code perform on this data when it gets processed? Where are the hyperparameters stored, and are they modifiable at runtime? Does the application use third-party libraries, frameworks, middleware, or web service APIs as part of the workflow that handles user input? If so, which ones?
Each of these questions can indicate potential attack targets. Each of them can hide vulnerabilities that attackers can exploit to achieve their original goals, as shown in the red boxes in the attack trees.
These vulnerability types are not related to ML as much as to the underlying technologies: the programming language itself (probably Python), the deployment environment (mobile, desktop, cloud), and the operating system. But the dangers they pose are just as critical as the adversarial examples – successful exploitation can lead to a full compromise of the ML
system. This is not restricted to the code of the application itself, either; see Security Risks in Deep Learning Implementations and Summoning Demons: The Pursuit of Exploitable Bugs in Machine Learning for two recent papers that explore vulnerabilities in commonly-used platforms such as TensorFlow and PyTorch, for example.
Threats are real
The main message is: machine learning security covers many real threats. Not only it is a subset of cyber security, but also shares many traits of software security. We should be concerned about malicious samples and adversarial learning, but also about all the common software security weaknesses. Machine learning is software after all.
Machine learning security is a new discipline. Research has just begun, we are just starting to understand the threats, the possible weaknesses, and the vulnerabilities. Nevertheless, machine learning experts can learn a lot from software security. The last couple of decades have taught us lots of lessons there.
Let’s work together on this!
We cover all of the aspects of machine learning security – and much more – in our Machine learning security course. In addition to talking about all of the threats mentioned in this article, our course also discusses the various protection measures (adversarial training and provable defenses) as well as other technologies that can make machine learning more secure to use in a cloud environment – such as fully homomorphic encryption (FHE) and multi-party computation.