In kernel space, no one can hear you panic
On July 19th, a significant portion of global IT infrastructure came to a grinding halt, due to computers running Windows crashing with the dreaded ‘Blue screen of death’ (BSOD). They all ended up in an unrecoverable state, as the affected machines would blue screen repeatedly during any subsequent boot-up. This outage affected airlines and other transport companies, emergency operators (911) and other governmental services, banks, media firms, and medical clinics. What triggered all this was a faulty update file for the CrowdStrike Falcon Sensor Endpoint Detection & Response (EDR) product. This was not an attack this time – the file that caused trouble was genuinely sent from the servers of CrowdStrike.
If this were a cyberattack, this would’ve been one of the most devastating cyberattacks of all time. For comparison, WannaCry in 2017 ‘only’ impacted about 300 thousand computers worldwide, while CrowdStrike disabled over 8.5 million! What’s worse: the issue prevented machines from starting, so physical human intervention was needed to fix it. This was rather difficult for some organizations with small or outsourced IT teams.
Just like with other devastating cyber incidents, there’s a vulnerability at the heart of it all. It’s usually a tiny mistake someone made deep in the code. Understanding these errors is critical to make sure they don’t happen again, whether we’re talking about accidental outages or intentional attacks. Not all information about this bug is known at this point, but there are clear indications about the type of the mistakes CrowdStrike made.
As a side note: even though this was not technically a cyberattack, many bad actors tried to take advantage of it by distributing malware disguised as ‘recovery manuals’ or phishing attacks by pretending to be official support.
Those dreaded ‘logic errors’!
Shortly after the incident, CrowdStrike has released limited technical details: in short, a channel file (a data file containing detection data updates for the Falcon Sensor product) named C-00000291-*.sys (the filename was unique for each user) for certain malware communication patterns was “triggering a logic error that resulted in the operating system crash”. Note that this was a data file (Rapid Response Content) update, while the code (Sensor Content) was unchanged – which is why the way to resolve the boot loop was to delete the offending file. This was followed up on July 24th by a preliminary post incident review that further specified the type of update content. Specifically, it was an IPC Template Instance, an instance of the IPC Template Type – actual code that is executed to monitor, detect or prevent activity from malware using inter-process communication channels (called named pipes in Windows:). The update was sent from the Content Configuration System in the cloud to the Content Interpreter running on the target machine.
Then disaster struck: due to an undisclosed bug in the Content Validator (which is part of the delivery system on the cloud), a malformed Template Instance went through the check and was distributed to all clients. This is highlighted in the most critical part of the report:
“When received by the sensor and loaded into the Content Interpreter, problematic content in Channel File 291 resulted in an out-of-bounds memory read triggering an exception. This unexpected exception could not be gracefully handled, resulting in a Windows operating system crash (BSOD).”
One Ring 0 bug to crash them all
What was this bug, then? A full root cause analysis of the vulnerable code hasn’t been released yet. There isn’t a CVE reserved for it either. And without knowing the source code or reverse engineering CrowdStrike’s kernel driver, we can only speculate. The content format is proprietary, after all.
The update process for Rapid Response Content sounds like object deserialization: a serialized stream is sent from the cloud to the CrowdStrike client, which then deserializes it and uses the data in it to instantiate the template and make it do specific things to deal with a certain type of an attack. Deserialization of untrusted data as well as dynamically modifying variables based on untrusted data are well-known vulnerability types. If the data is corrupt, incomplete, or contains incorrect pointers, this can potentially crash the target machine. In the worst case, the attacker can execute arbitrary code – just consider Log4Shell for an extreme example, though of course that vulnerability had a very different context.
Some questions come to mind about the content file. Does a part of it contain actual code to be loaded into memory? Does it contain byte sequences that are converted to memory addresses and used directly as function pointers? Or maybe it contains integers that are used to index tables which contain function pointers? If so, are those tables also populated from the file, or are they pre-existing? Is there a digital signature section or any other data that’s pre-processed before deserialization, and what happens if that data is malformed or truncated? But even with limited information, there is enough evidence out there to draw some conclusions.
Let’s first look at an answer that turned out to be wrong! Early on there were scattered reports of corrupted .sys files filled with NUL (0x00) bytes. This has led to a popular, but wrong claim about the root cause being a NULL pointer dereference. Not only does this go against the details disclosed by CrowdStrike, but a quick analysis by well-known security researcher Tavis Ormandy confirmed that there was an explicit NULL check in the code (TEST R8, R8) just a few lines before the crash – and besides, the assembly code would look different if it was attempting to index a struct with an offset from the starting 0x00 address. Therefore, we can rule this out.

Disassembly of the crashing code (source: taviso)
Let’s see if we can draw any conclusions about the nature of the bug by looking at the evidence as posted and analyzed by Patrick Wardle (prior to CrowdStrike’s explanatory post):
Code snippet reverse engineered by Patrick Wardle
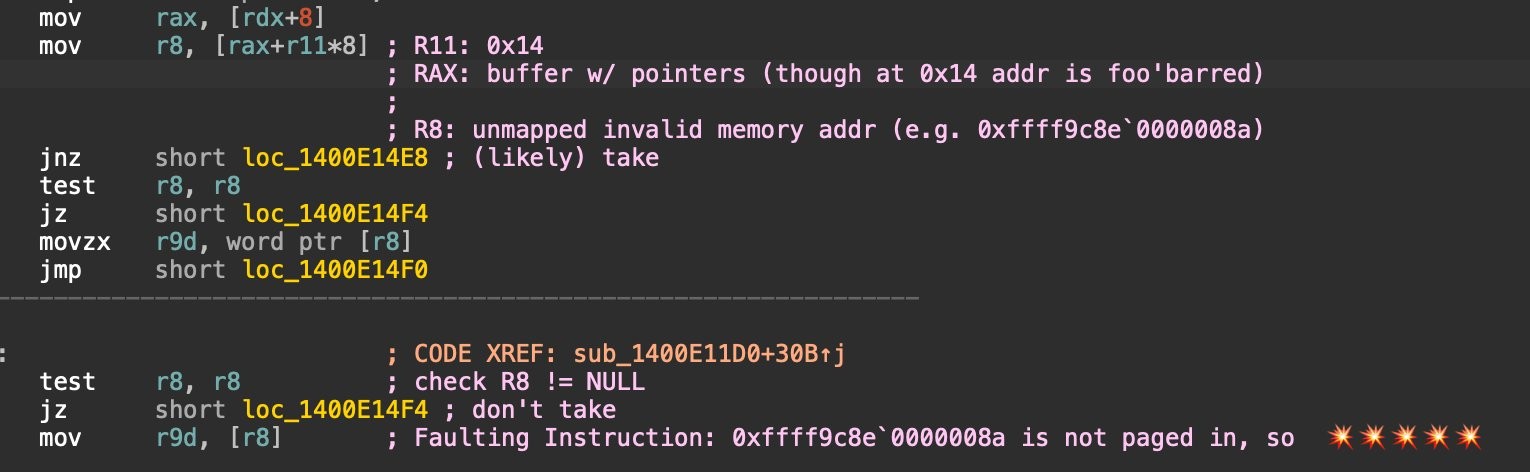
- The BSOD caused by CrowdStrike was due to attempting to access unmapped memory. This happened during boot, in kernel space – as a driver, CSAgent.sys runs at Ring 0, equivalent to the OS’ own code. A similar bug in user mode would’ve just terminated the offending program.
- Reverse engineering of the vulnerable driver file CSAgent.sys shows that before the time of the crash, R8 was supposed to contain an address read from an array of 8-byte values (i.e. a buffer containing pointers) based on the R11 register’s value (MOV R8, [RAX+R11*8] where RAX is pointing at the beginning of this array). If R11 was too big and pointed outside the bounds of the array here, R8’s value became uninitialized ‘garbage’ data (likely containing many 0x00 bytes).
- There was an explicit check for R8 against zero. Which was good. But there was no checking on whether it pointed to a valid memory address.
- The MOV instruction attempted to read data from the memory location pointed by R8 (almost guaranteed to be an invalid memory address). This caused the PAGE_FAULT_IN_NONPAGED_AREA.
- The exact name and content of the Rapid Response Content .sys files may have been different between systems, but deleting the malformed file always fixed the crash.
- According to MalwareUtkonos, there is a ‘magic’ value for the channel files that has to be 0xAAAAAAAA (i.e. the file has to start with this byte sequence or isn’t processed at all).
These clearly show that an all-zero file is not to blame here. However, the CrowdStrike code performing the out-of-bounds memory access (array over-indexing or buffer over-read) strongly suggests that the register used for it (R11) took its value from data read from the file in question. Whether this operation takes place during pre-processing (e.g. signature verification) or during the actual deserialization doesn’t really matter – the issue is a combination of the following:
- Not performing input validation on the endpoint (Content Interpreter) on all untrusted or potentially malformed data that is used to index memory directly or indirectly. Range checking could have certainly prevented the out-of-bounds memory access.
- Not having robust error handling in place. Erroneous input can enter the system for a variety of reasons (not all of them malicious), but it should be caught and handled before it causes a BSOD or kernel panic.
At a high level, the code was trusting the data received from the cloud to always be correct. This also led to a lack of security testing of the functions on the endpoint that are responsible for processing the data. This is independent of any bugs in the Content Validator in the cloud – even if CrowdStrike assumed an ideal scenario where the data had previously been validated by that component and it’s impossible for an attacker to trick or defeat the validation process, this pre-validated data may have gotten corrupted or damaged before it actually made it to the client.
At least minimal validation that makes sense in the context of its use (range checking) should have been performed on it again. And to be fair, some validation was performed – there was a magic check for the file and the pointer was checked for zero before dereferencing – but the function should’ve also checked that it was reading data only from within the boundaries of the target array.
The be-all and end(point)-all of security?
This debacle has caused a lot of heated discussion about the relationship between security software and software security. After all, security is about risk management: to grossly oversimplify the concept, we spend X amount of money to reduce the expected damage (risk) from attacks by Y. And of course, we do this in a smart way if X is much less than Y. In this specific case however, many companies applied the security software of CrowdStrike to manage their risk, while at the end a software security related issue in it caused much more damage than it prevented in the first place.
In general, a lot of the security industry today revolves around endpoint security and response (EDR), a buzzword-laden evolution of intrusion detection and prevention systems (IDPS) that detect anomalous and suspicious activity either on the network, or on a particular host. These tools also integrate incident handling and response capabilities, and are frequently SaaS products supported by machine learning models (AI) that try to detect unusual activity.
This is not entirely without merit. Of course, the best way to protect against threats is to prevent them – developers should not write vulnerable code in the first place; the code should not run suspicious executables downloaded from untrustworthy sites; applications shouldn’t allow external access to sensitive resources; and one should remove unnecessary components that expand the attack surface – among others. But still, there is value in tools that can detect (or even react to) yet unknown attacks in real time, and log suspicious activities to help identify the attacker and the extent of their activities during a later investigation, especially since without these tools, many victims may not even realize they got hacked. “Insufficient Logging & Monitoring” appeared on the OWASP Top 10 in 2017 (and stayed on the list in 2021 as “Security Logging and Monitoring Failures”), but not without controversy – its original submission as “Insufficient Attack Protection” was suspected to promote such products in the guise of application security advocacy and was removed after discussions.
From a technical standpoint, in order to protect against malware and other threats effectively, it is necessary for EDR software like CrowdStrike to run at very high privilege levels. In the kernel this means running at Ring 0. Code like that needs to be rigorously reviewed and vetted, since a bug can cause the entire OS to halt. Even worse, it may also allow the attacker to execute code at Ring 0, which basically means a full takeover of the OS (as seen with EternalBlue and WannaCry in 2017). The driver in question (csagent.sys) had to go through Windows Hardware Certification (previously WHQL) to get digitally signed by Microsoft. However, Microsoft cannot account for the driver dynamically loading or executing custom code (if indeed that was the case), and the disaster wasn’t caused by a change to the code of the driver itself.
Thankfully this isn’t a universal problem, as other operating systems have developed (or are in the process of developing) ways to run such code with lower privileges so that even a crash doesn’t destroy everything. In Linux, this is possible via the Berkeley Packet Filter (BPF) that heavily sandboxes code to prevent it from harming the OS by accident; on Macs, kernel extensions (kexts) were deprecated and the interfaces necessary for anti-virus and similar software are accessible via user-mode System Extensions instead. That said, the Linux version of CrowdStrike Falcon Sensor has also caused kernel panics earlier this year, indicating that the problem is not Windows-specific and may have been around for a while – possibly deeply embedded in one of the platform’s core components.
When data is not just data
A recurring theme in this incident was a confusion between (and sometimes conflation of) data and code updates. CrowdStrike strongly underlined in the preliminary post incident review that the code of the actual driver (Sensor Content) was extensively tested, undergoing “dogfooding”, staged rollouts, and the usual CI/CD security processes. CrowdStrike claims to have performed extensive testing on the IPC Template Type, since it’s part of the actual code running on the endpoints after all. Several Template Instances were also released for it without incident.
But the issue was caused by malformed data in the regularly distributed updates to clients (Rapid Response Content), and that content has not undergone any kind of strenuous testing – after all, it was “just data”. While some testing was performed (“For each Template Type, a specific Template Instance is used to stress test the Template Type by matching against any possible value of the associated data fields to identify adverse system interactions”), it was clearly insufficient.
In fact, in the “How Do We Prevent This From Happening Again?” section of the post, CrowdStrike lists various testing techniques to be applied to Rapid Response Content in the future: local testing, content update and rollback testing, stress testing, fuzzing and fault injection, stability testing and content interface testing. This implies that such testing (e.g. “what happens if we push an update with an accidentally malformed file?”) wasn’t done beforehand, which is extremely dangerous when dealing with what is, effectively, object deserialization in kernel code.
In the process of deserialization, the stream (the .sys file containing the updated content) gets turned into an object on the client. If the stream is malformed and contains invalid values for certain fields, this can easily cause invalid memory access. However, since the code is running in Ring 0, this leads to kernel panics. In a hypothetical scenario, if an attacker could have somehow manipulated this process, they could potentially inject their own code to be executed with full privileges. This means that they can effectively take over every machine managed by this product and gain immediate control of a botnet of 8.5-million machines!
Keep your pointers inside the buffer at all times
In languages like C and C++ developers have full control of the memory, and they should handle it safely. But with great power comes great responsibility! It’s easy to make mistakes here, and buffer overflows, use-after-free errors and similar vulnerabilities are unfortunately very commonplace. These vulnerabilities are not obvious at all. The program may appear to work correctly until it receives input of just the right size, causing it to overwrite something critical in memory or try to access unmapped memory and crash. These vulnerabilities are further amplified in kernel code, where an attacker may be able to evade typical protections like NX/DEP at will and address space randomization may be easier to defeat as well.
That said, some good news. Vulnerabilities related to out-of-bounds memory access and use of ‘wild pointers’ referencing uninitialized or unmapped memory are well-known at this point. There are many ways of dealing with them (of course not all apply to this specific case).
- Ideally, such situations can be prevented by appropriate input validation in the function that handles the potentially incorrect data: always check that the pointer in question is not NULL and that it points inside the object in question (for example, before using buffer[index], the code should check if index is between 0 and (buffer size-1)).
- Robust error handling complements input validation by anticipating and handling such error situations and either recovering from them (if possible), or exiting gracefully (if not).
- Before processing the input file, its integrity should be verified, for example by using digital signatures. Though, note that malformed digital signatures can also cause issues if not handled correctly! Afterwards, the structure of the input file should be checked as well (e.g. via JSON or XML schemas).
- Testing tools such as AddressSanitizer (and to an extent, Valgrind) can find these kinds of memory errors, even if the errors are normally ‘invisible’ to the tester.
- Fuzz testing tools such as AFL/AFLplusplus can automatically find such issues by systematically generating many malformed test vectors and testing the program’s behavior with them.
- Numerous compiler options exist that either detect these errors at compile time, or harden the executable to help discover them or make their exploitation harder.
An important thing to keep in mind is defense in depth. Having multiple levels of protection is beneficial. Even if one of them fails, the other layers can prevent disaster or exploitation. In this particular case, the CrowdStrike’s Content Validator preventing the server from sending out malformed update content was a good idea, but repeating some of those validation steps on the Content Interpreter could prevent problems arising from accidental (or intentional) data corruption.
Following secure coding best practices can prevent out-of-bounds memory reads and similar vulnerabilities. Learn more about buffer overflows, use-after-free errors, improper pointer handling, and most importantly, the best practices to deal with them – to make sure the next world-shaking vulnerability doesn’t pop up in your code!