Apache SSRF: an all-you-can-eat reverse proxy
How do Server Side Request Forgery (SSRF) vulnerabilities manifest in code? A recent SSRF in Apache can help us understand.

Server-Side Request Forgery (SSRF) vulnerabilities have been on the rise, targeting Internet-facing applications of all shapes and sizes; there is a reason why SSRF is its own entry on the OWASP Top 10 2021. A particularly damaging SSRF vulnerability was recently discovered in the Apache web server (also called httpd or just Apache for short) that merits a deeper look to understand just how much damage these vulnerabilities can do.
In order to understand the vulnerability’s scope, we’ll need some context about Apache itself first.
When you’re on top, you’re also the top target
While it may not be obvious today, the World Wide Web as we know it was largely built on the Apache HTTP server. It is free and open source software that has been powering many web servers all over the world since 1995. Despite a slow decline in popularity, it is still (as of November 2021) maintaining a steady #2 spot behind nginx (which itself was developed as a simpler, more performant competitor for Apache). Even in modern web applications that use lightweight application servers like Python’s Flask to generate dynamic content, the architecture will likely use either Apache or nginx to serve the application’s static files and act as a proxy for load balancing purposes. All of this also means that Apache has always been an enticing target for attackers. For example, several recent vulnerabilities (CVE-2021-41773 and especially CVE-2021-42013) allowed code execution via path traversal, and have been active targets of exploitation by cybercriminals in October 2021.
So where does SSRF come into the picture?
The answer is simple: SSRF attacks are a prime way of getting around a perimeter of a system by tricking a trusted Internet-facing component (like Apache!) to do the attacker’s bidding. If the architect puts too much trust into the internal network being inaccessible ‘from the outside’ – especially if it’s a self-hosted Web infrastructure – they can get a nasty surprise if such a vulnerability is exploited.
There is never “just one” CVE…
Thankfully, unlike the path traversal vulnerabilities above, this SSRF vulnerability – CVE-2021-40438 – was discovered internally in version 2.4.48 by the Apache team, and probably hasn’t been exploited by the bad guys at that point yet. To be more precise, it was found when the Apache team was investigating another vulnerability related to a buffer over-read possibility (CVE-2021-36160). Regardless, it is a critical vulnerability with a CVSS score of 9.0 (Critical), which puts it at the high end for SSRF vulnerabilities – after all, many SSRF vulnerabilities only impact confidentiality, but this one impacts all three requirements of the CIA triad (confidentiality, integrity and availability).
So how is it exploited? Well, like this (as tweeted by @_mattata):
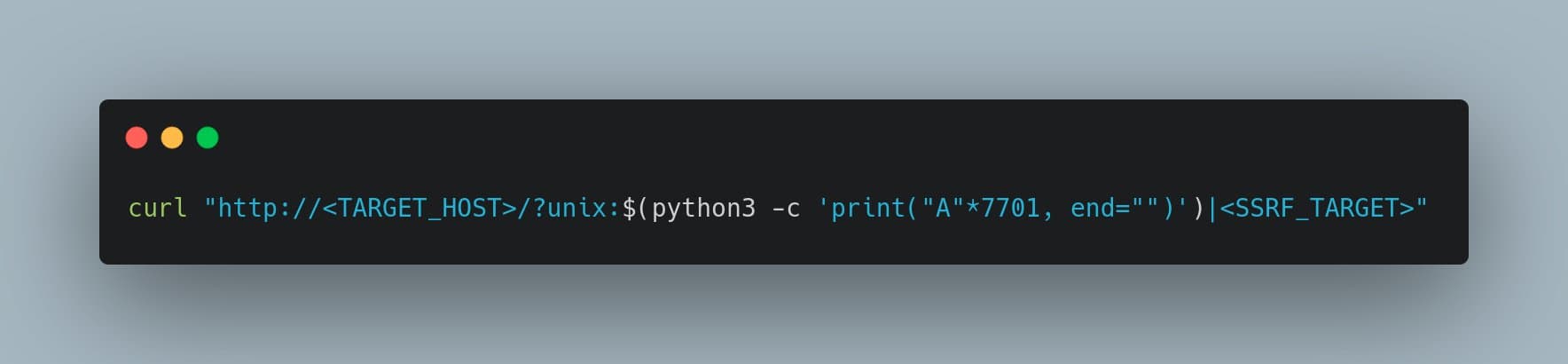
To paraphrase the above tweet a bit, the attacker makes a request like
http://example.com/?unix:AAA …[7701 ‘A’ characters total]… A|http://192.168.1.2/something_dangerous
This request then forces the Apache server to make a GET request to the internal
http://192.168.1.2/something_dangerous
address – a classic example of SSRF.
Having 7701 ‘A’ characters next to each other in the URL definitely indicates some sort of buffer size and/or error handling issue, and the unix: part of the URL looks non-standard. Both of these things should give us pause, because the former indicates an underlying problem buried somewhere deep in the source code, and the latter looks like a possible dangerous functionality (proxying external HTTP requests to a Unix Domain Socket) that may not have undergone extensive security analysis. Indeed, UDS proxying is only available since Apache 2.4.7 (2013).
Let’s look at the code to identify the root cause and see how it was fixed!
Validate your inputs, or do not, there is no ‘try’
Since this SSRF was an internal finding, Apache have been understandably tight-lipped about it, but a comment in the bug tracker entry for a regression hints at the cause in context of the independently reported CVE-2021-36160 vulnerability:
“[…] further (internal-)analysis of the exploit (ed: CVE-2021-36160) showed that similar techniques could cause other flaws elsewhere so we fixed that in r1892874 and issued CVE-2021-40438.”
Looking at the revision in question, it seems to change some validation within the URI. Let’s put the change in context so we understand what caused the SSRF. The code from the revision points out the change within fix_uds_filename() in proxy_util.c (the two critical parts of the condition are underlined):
static void fix_uds_filename(request_rec *r, char **url) { char *ptr, *ptr2; if (!r || !r->filename) return; if ( !strncmp(r->filename, "proxy:", 6) && (ptr2 = ap_strcasestr(r->filename, "unix:"))&& (ptr = ap_strchr(ptr2, '|')) ) { apr_uri_t urisock; apr_status_t rv; *ptr = '\0'; rv = apr_uri_parse(r->pool, ptr2, &urisock); if (rv == APR_SUCCESS) { char *rurl = ptr+1; char *sockpath = ap_runtime_dir_relative(r->pool, urisock.path); apr_table_setn(r->notes, "uds_path", sockpath); *url = apr_pstrdup(r->pool, rurl); /* so we get the scheme for the uds */ /* r->filename starts w/ "proxy:", so add after that */ memmove(r->filename+6, rurl, strlen(rurl)+1); ap_log_rerror(APLOG_MARK, APLOG_TRACE2, 0, r, "*: rewrite of url due to UDS(%s): %s (%s)", sockpath, *url, r->filename); } else { *ptr = '|'; } } }
After the fix, the two underlined lines were replaced with the following code:
… !ap_cstr_casecmpn(r->filename + 6, "unix:", 5) && (ptr2 = r->filename + 6 + 5, ptr = ap_strchr(ptr2, '|'))) { …
This helper function rewrites URIs that use UDS (Unix Domain Socket) redirection within mod_proxy, which is one of the core modules for Apache (especially in two of its main use cases: forward and reverse proxy). The general workflow is to extract the actual URI to use for redirection by locating the unix: string somewhere in the URI eventually followed by a filename and a pipe (|) character; the filename identifies the domain socket, then the proxy needs to redirect whatever is after the pipe character to it. It’s important to note that such a URI should only be generated internally by Apache itself; it should not come from the outside, as access to arbitrary domain sockets is by itself a potential SSRF.
What the fix changed was the definition of a valid proxy URI: after the fix if the URI had to immediately start with ‘proxy:unix:‘ – beforehand, it would be considered acceptable as long as the URI contained ‘unix:‘ in it somewhere (all strings are case-insensitive). This was a classic issue of overly lenient input validation – if we have an assumption about what the input should look like (in this case, starting with ‘proxy:unix:‘), we should explicitly check for that instead of a weaker condition. This difference is very significant – before the fix, the attacker could send an HTTP request such as http://example.com/?unix:socket_name|http://some_other_url and after it was translated into a proxy request, it’d look like proxy:http://example.com/?unix:socket_name|http://some_other_url. We are clearly proxying an HTTP request here, but since unix: is present in the string, it would be accepted as a valid request for UDS proxy redirection, and the code would run. After the fix, an attacker couldn’t send any more an HTTP request that’d trigger a valid UDS proxy request simply because the request URL always started with http.
How a simple unchecked return value can start an avalanche
Now we have seen the first part of the problem, but how do we get to an SSRF from here? The answer to that lies deeper in the code.
Consider that the string had to be very long for the attack to succeed – so let’s see how the code parsed the UDS path. It first invoked ap_runtime_dir_relative() which eventually called apr_filepath_merge() in filepath.c of the Apache Portable Runtime library. That function returned an error if length of the file path plus 4 (for slashes) plus the root path’s length was over the APR_PATH_MAX value, therefore limiting input length (which is good!):
rootlen = strlen(rootpath); maxlen = rootlen + strlen(addpath) + 4; /* 4 for slashes at start, after * root, and at end, plus trailing * null */ if (maxlen > APR_PATH_MAX) { return APR_ENAMETOOLONG; }
When this happened, ap_runtime_dir_relative() considered it an error scenario and it returned NULL:
rv = apr_filepath_merge(&newpath, runtime_dir, file, APR_FILEPATH_TRUENAME, p); if (newpath && ( rv == APR_SUCCESS || APR_STATUS_IS_EPATHWILD(rv) || APR_STATUS_IS_ENOENT(rv) || APR_STATUS_IS_ENOTDIR(rv)) ){ return newpath; } else { return NULL; }
So far so good – there was some code in place to enforce an upper limit on the length of an input, and it returned an appropriate error value. Its caller function appropriately handled the error and returned NULL if anything went wrong. Perhaps the error it returned could be more descriptive, but at least it’s clear: when a function is supposed to return a string, a NULL return value means something is wrong.
The problem was in fix_uds_filename() (again). This is the function that called ap_runtime_dir_relative(). The two relevant lines from the code were:<
char *sockpath = ap_runtime_dir_relative(r->pool, urisock.path); apr_table_setn(r->notes, "uds_path", sockpath);
This code had no error checking at all! If ap_runtime_dir_relative() returned a NULL, it would just assign it to sockpath and write it into the uds_path entry within the notes table (a kind of dynamic container).
If we look at the code much later in the workflow that is in charge of preparing the proxy connection, it all hinges on a simple condition. In pseudocode, the code flow is basically (uds_path is the uds_path entry within the notes table, see above):
if (uds_path) { // Prepare UDS request… } else { // Prepare standard proxy request… }
Since uds_path was set to NULL at this point, it caused the code in charge of preparing the proxy connection to go down the wrong execution path and interpret the request as a standard proxy request to http://some_other_url. At that point, this request was executed and the SSRF exploit was successful. At that point, the attacker could send a request to any Apache server within the target’s internal network!
If you want a more detailed look at this workflow (including a look at how a hacker would go from identifying the vulnerability to reverse engineering the code and creating a full exploit in a real environment), we recommend this excellent writeup on firzen.de.
All is well that ends well
This example shows us quite a few things about input validation and error handling. The obvious takeaway is: strict input validation is good! After all, that’s what the fix did: by requiring the URI to start with ‘proxy:unix:‘, it was no longer possible to misunderstand an HTTP request from the outside as a request to proxy a request over to a UDS.
But that’s not the entire story – even with the lax interpretation of UDS filenames, it wouldn’t have been possible to exploit this vulnerability if there was a proper error handling in place. In particular, fix_uds_filename() didn’t check if ap_runtime_dir_relative() returned with an error (indicated by a NULL), it just blindly placed the return value into a table, even if it was NULL. And this had some non-obvious side effects when the connection was actually prepared later. On a ‘meta level’, the relationship between the two different vulnerabilities found in Apache is likewise interesting and highlights how vulnerabilities are not in a vacuum – they are often enablers of each other.
An important concept of secure coding is defense in depth: having a (healthy!) level of paranoia about functions going wrong, generating errors, or just returning incorrect results, and making sure the code is prepared for these situations via sanity checks.
Which is exactly what Apache did in a subsequent patch: fix_uds_filename() was significantly rewritten – for one thing, it now had a return value. When ap_runtime_dir_relative() returned NULL, the function logged the error and also returned 0, which then translated into a HTTP_SERVER_ERROR (status code 500) response to the client. All things considered, the vulnerability was fixed appropriately.
Following secure coding best practices can prevent issues like this. Learn more about input validation, SSRF, and best practices to make sure vulnerabilities like this don’t pop up in your code! Check out all courses in our catalog, and keep coding responsibly!